how to cheat at settlers by loading the dice
(and prove it with p-values)
tl;dr This post shows how to create loaded dice, and how to use these dice to gain between 5-15 additional resource cards per game of Settlers of Catan. Surprisingly, we’ll prove that standard scientific tests are not powerful enough to determine that the dice are unfair while playing a game. This essentially means that it’s impossible for your opponents to scientifically prove that you’re cheating. This impossibility is due to methodological defects in the current state of scientific practice, and we’ll highlight some ongoing work to fix these defects.

Loading the dice
My copy of Settlers of Catan came with two normal wooden dice. To load these dice, I placed them in a small plate of water overnight, leaving the 6 side exposed.

The submerged area absorbed water, becoming heavier. My hope was that when rolled, the heavier wet sides would be more likely to land face down, and the lighter dry side would be more likely to land face up. So by leaving the 6 exposed, I was hoping to create dice that roll 6’s more often.
This effect is called the bias of the dice. To measure this bias, my wife and I spent the next 7 days rolling dice while eating dinner. (She must love me a lot!)

In total, we rolled the dice 4310 times. The raw results are shown below.

| 1 | 2 | 3 | 4 | 5 | 6 | |
| number of rolls | 622 | 698 | 650 | 684 | 666 | 812 |
| probability | 0.151 | 0.169 | 0.157 | 0.165 | 0.161 | 0.196 |
Looking at the data, it’s “obvious” that our dice are biased: The 6 gets rolled more times than any of the other numbers. Before we prove this bias formally, however, let’s design a strategy to exploit this bias while playing Settlers of Catan.
A strategy for loaded dice
The key to winning at Settlers of Catan is to get a lot of resources. We want to figure out how many extra resources we can get using our biased dice.
First, let’s quickly review the rules. Each settlement is placed on the corner of three tiles, and each tile has a number token. Whenever the dice are rolled, if they add up to one of the numbers on the tokens, you collect the corresponding resource card. For example:

A good settlement will be placed next to numbers that will be rolled often.
To make strategizing easier, the game designers put helpful dots on each token below the number. These dots count the ways to roll that token’s number using two dice.

We can use these dots to calculate the probability of rolling each number. For example, a \(4\) can be rolled in three ways. If we name our two dice \(A\) and \(B\), then the possible combinations are \((A=1,B=3)\), \((A=2,B=2)\), \((A=3,B=1)\). To calculate the probability of rolling a 4, we calculate the probability of each of these rolls and add them together. For fair dice, the probability of every roll is the same \((1/6)\), so the calculation is:
\[\begin{align} Pr(A+B = 4) &= Pr(A = 1)Pr(B=3) + Pr(A=2)Pr(B=2) + Pr(A=3)Pr(B=1) \\ &= (1/6)(1/6) + (1/6)(1/6) + (1/6)(1/6) \\ &= 1/12 \\ &\approx 0.08333 \end{align}\]For our biased dice, the probability of each roll is different. Using the numbers from the table above, we get:
\[\begin{align} Pr(A+B = 4) &= Pr(A = 1)Pr(B=3) + Pr(A=2)Pr(B=2) + Pr(A=3)Pr(B=1) \\ &= (0.151)(0.157) + (0.169)(0.169) + (0.157)(0.151) \\ &= 0.07597 \end{align}\]So rolling a \(4\) is now less likely with our biased dice. Performing this calculation for each possible number gives us the following chart.

All the numbers below \(7\) are now less likely, and the numbers above 7 are now more likely. The shift is small, but it has important strategic implications.
Consider the two initial settlement placements below.

The naughty player knows that the dice are biased and puts her settlements on locations with high numbers, but the nice player doesn’t know the dice are biased and puts her settlements on locations with low numbers. Notice that if the dice were fair, both settlement locations would be equally good because they have the same number of dots.
The following formula calculates the average number of cards a player receives on each dice roll:
\[ \text{expected cards per roll} = \sum_{\text{adjacent tokens}} Pr(A+B=\text{token value}) \]
Substituting the appropriate values gives us the following results.
|
|
||
| naughty | nice | |
| fair dice | 0.500 | 0.500 |
| biased dice | 0.543 | 0.457 |
So the difference between the naughty and nice player is \(0.086\) cards per roll of the biased dice. A typical game of Settlers contains about 60 dice rolls (about 15 turns per player in a 4 player game), so this results in \(0.086*60=5.16\) more cards for the naughty player.
And this is only considering the two starting settlements. As the game progresses, more settlements will be built, and some settlements will be upgraded to cities (which receive two cards per roll instead of one). Calculating the exact effect of these additional sources of cards is difficult because these improvements will be built at random points throughout the game. We’ll have to make some additional assumptions.
If we assume that the naughty player gets 0.043 more cards per roll per settlement/city than the nice player (this exact number will vary depending on the quality of the settlement), and that both players build settlement/cities at turns 10,20,25,30,35,40,45, and 50, then the naughty player will on average receive 15.050 more cards than the nice player.
To summarize, the naughty player will receive somewhere between 5 and 15 more resource cards depending on how their future settlements and cities are built. This advantage can’t guarantee a victory, but it’ll definitely help.
A scientific analysis
Now we’re going to do some simple statistics to prove two things:- The dice really are biased. So the fact that the 6 was rolled more times than the other numbers wasn’t just due to random chance.
- There are not enough dice rolls in a game of Settlers for our opponents to scientifically prove that the dice are biased. So it’s scientifically impossible for our opponents to know that we’re cheating.
To show that the dice are biased, we will use a standard scientific technique called null hypothesis significance testing. We begin by assuming a hypothesis that we want to disprove. In our case, we assume that the dice are not biased. In other words, we assume that each number on the dice has a \(1/6\approx 0.166\) chance of being rolled. Our goal is to show that under this assumption, the number of 6’s rolled above is very unlikely. We therefore conclude that our hypothesis is also unlikely, and that the dice probably are in fact biased.
More formally, we let \(X\) be a random variable that represents the total number of 6’s we would roll if we were to repeat our initial experiment with fair dice. Then \(X\) follows a binomial distribution whose density is plotted below.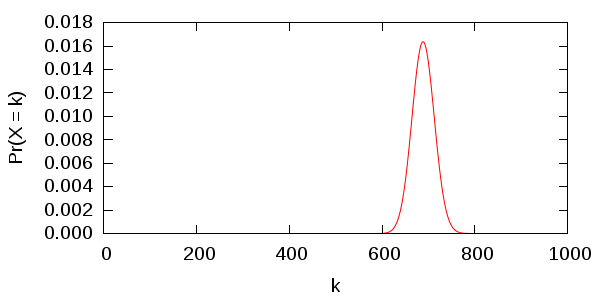
where \(n\) is the total number of dice rolls (4310), \(k\) is the number of 6’s actually rolled (812), and \(q\) is the assumed probability of rolling a 6 (1/6). Substituting these numbers gives us \[ p\text{-value}= Pr(X\ge k) \approx 0.0000884 . \] In other words, if we repeated this experiment one million times with fair dice, we would expect to get results similar to the results we actually got only 88 times. Since this is so unlikely, we conclude that our original assumption (that the dice are not biased) is probably false. Most science classes teach that \(p\)-values less than 0.05 are “significant.” We are very far below that threshold, so our result is “very significant.”
Our \(p\)-value is so low because the number of trials we conducted was very large \((n=4310)\). In a typical game of Settlers, however, there will be many fewer trials. This makes it hard for our opponents to prove that we’re cheating.
We said before that there are 60 dice rolls in a typical game. Since we have two dice, that means \(n=120\). To keep the math simple, we’ll assume that we role an average number of 6’s. That is, the number of sixes rolled during the game is \[ k=812\cdot \frac{120}{4310}\approx23. \] Substituting into our formula for the \(p\)-value, we get \[ p\text{-value}=P(X\ge k) \approx 0.265 . \] In words, this means that if the dice were actually fair, then we would still role this number of 6’s \(26.5\%\) of the time. Since this probability is so high, the standard scientific protocol tells us to conclude that we have no “significant” evidence that the dice are biased. (Notice that this is subtly different from having evidence that the dice are not biased! Confusing these two statements is a common mistake, even for trained phd scientists, and especially for medical doctors.)
So how many games can we play without getting caught? It turns out that if we play 6 games (so \(n=6*120=720\), and \(k=812\cdot(720/4310)\approx136\)), then the resulting \(p\)-value is 0.05. In other words, as long as we play fewer than 6 games, then our opponents won’t have enough data to conclude that their measurements of the biased dice are “significant.” The standard scientific method won’t prove we’re cheating.
Some flaws with the \(p\)-value and “significance”
The \(p\)-value argument above is how most scientists currently test their hypotheses. But there’s some major flaws with this approach. For example:
-
The \(p\)-value test doesn’t use all the available information. In particular, our opponents may have other reasons to believe that the dice are loaded. If you look closely at the dice, you’ll notice some slight discoloration where it was submerged in water.

This discoloration was caused because the water spread the ink on the die’s face. If you see similar discoloration on the dice in your game, it makes sense to be extra suspicious about the dice’s bias.
Unfortunately, there’s no way to incorporate this suspicion into the \(p\)-value analysis we conducted above. An alternative to the \(p\)-value called the bayes factor can incorporate this prior evidence. So if our opponent uses a bayes factor analysis, they may be able to determine that we’re cheating. The bayes factor is more complicated than the \(p\)-value, however, and so it is not widely taught to undergraduate science majors. It is rarely even used in phd-level scientific publications, and many statisticians are calling for increased use of these more sophisticated analysis techniques.
-
Another weakness of the \(p\)-value test is that false positives are very common. Using the standard significance threshold of \(p\le0.05\) means that 5 of every 100 games will have “significant” evidence that the dice are biased to role 6’s. Common sense, however, tells us that cheating at Settlers of Catan is almost certainly not this common because most people just don’t want to cheat. But when you run many experiments, some of them will give “significant” results just by random chance. This is one of the many reasons why some scientists have concluded that most published research is false. This effect is thought to be one of the reasons that evidence of extra sensorial perception (ESP) continues to be published in scientific journals. Some less scrupulous scientists exploit this deficiency in a process called p-hacking to make their research seem more important.
To alleviate the problem of false positives, a group of statisticians is proposing a new significance threshold of \(p\le0.005\) for a result to qualify as “significant”. While this reduces the risk of false positives, it also makes detecting true effects harder. Under this new criterion, we’d have to play 16 games (for \(n=1920\) dice roles) to get statistically significant evidence that the dice are biased.
At this point, you might be feeling overwhelmed at the complexity of statistical analysis. And this is just for the toy problem of detecting loaded dice in a game. Real world problems like evaluating the effectiveness of chemotherapy drugs are much more complicated, and so require much more complicated statistical analyses. Doing science is hard!
Edit after peer review: Vijay Lulla sent me the following message:
The blog mentions that you rolled the dice 4310 times and all your calculations are based on it, but the frequency table adds up to 4312.
Whooops! It looks like a messed up my addition. Fortunately, this mistake is small enough that it won’t affect any of the numbers in the article by much.
A lot of people mistakenly think that peer review is where other scientists repeat an experiment to test the conclusion. But that’s not the case. The purpose for peer review is for scientists like Vijay to just do a sanity check on the whole procedure to make sure obvious mistakes like this get caught. Sadly, another commonly made mistake in science is that researchers don’t publish their data, so there’s no way for checks like this to be performed.
If this were a real publication in a scientific journal, I would redo all the calculations. But since it’s not, I’ll leave the mistake for posterity.
Edit 2: There’s a good discussion on reddit’s /r/statistics. This discussion provides a much more nuanced view about significance testing than my discussion above, and a few users point out ways that I might be overstating some conclusions.