HLearn cross-validates >400x faster than Weka

Weka is one of the most popular tools for data analysis. But Weka takes 70 minutes to perform leave-one-out cross-validate using a simple naive bayes classifier on the census income data set, whereas Haskell’s HLearn library only takes 9 seconds. Weka is 465x slower!
Code and instructions for reproducing these experiments are available on github.
Why is HLearn so much faster?
Well, it turns out that the bayesian classifier has the algebraic structure of a monoid, a group, and a vector space. HLearn uses a new cross-validation algorithm that can exploit these algebraic structures. The standard algorithm runs in time \(\Theta(kn)\), where \(k\) is the number of “folds” and \(n\) is the number of data points. The algebraic algorithms, however, run in time \(\Theta(n)\). In other words, it doesn’t matter how many folds we do, the run time is constant! And not only are we faster, but we get the exact same answer. Algebraic cross-validation is not an approximation, it’s just fast.
Here’s some run times for k-fold cross-validation on the census income data set. Notice that HLearn’s run time is constant as we add more folds.
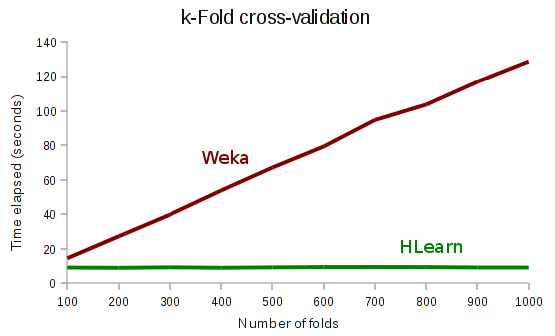
And when we set k=n, we have leave-one-out cross-validation. Notice that Weka’s cross-validation has quadratic run time, whereas HLearn has linear run time.
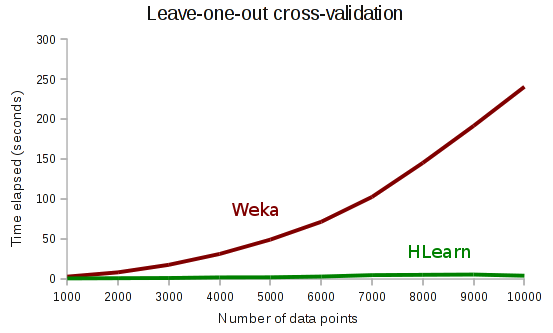
HLearn certainly isn’t going to replace Weka any time soon, but it’s got a number of cool tricks like this going on inside. If you want to read more, you should check out these two recent papers:
I’ll continue to write more about these tricks in future blog posts.